We have seen that if database tables are designed to represent a set of (facts about) a single class of attribute-sharing entities each and to preserve the mathematical properties of relations, databases are easier to understand, and query results are guaranteed to be provably correct and easier to interpret. Let's see how and why with the help of an example.
Consider numbers. They are abstract -- on their own they have no real world meaning. They areclosed to the algebra of numbers which we call arithmetic, i.e., when arithmetic operations are applied to one or more numbers, they produce a number as result, as a consequence of which the same operations can re-operate on the result (in other words, they are nestable). Importantly, neither the operations, nor the results are dependent on any meaning we may attach to the numbers: always 2+2=4, whether dollars, tomatoes, or anything else. This gives arithmetic versatility: it can be applied to any aspect of the real world. It's mathematics -- arithmetic -- that guarantees the correctness of results.
Sets are also abstractions. A relation is a set that is a relationship between sets called domains -- a subset of their Cartesian product. For example, the Cartesian product of the two domains:
{1,2} x {a,b}
is
1 a
1 b
2 a
2 b
and any subset of it, e.g.
1 b
2 a
is a relation, in this case binary, because it is a relation on two domains. The members of the relation -- themselves sets of values, one from each domain -- are tuples, here {1,b} and {2,a}.
Just like numbers are closed to numeric algebra, relations are closed to the relational algebra: its operations take one or more relations and yield a relation and are, thus, nestable. Neither operations nor results depend on any meaning we may attach to the relations and the underlying mathematics guarantees the correctness of results. So we can use relations to represent any aspect of the real world and take advantage of that guarantee.
Consider, for example, a set of facts about employees.
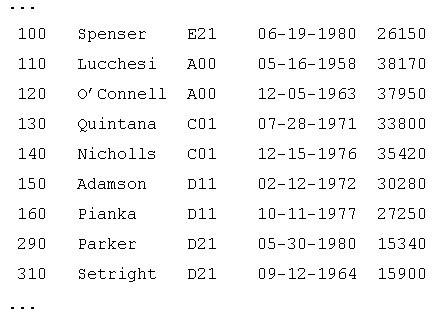
The dots imply that it is a subset of the Cartesian product of five domains -- a relation.
- Domains could represent properties, sets of values deemed valid by the enterprise and, therefore, possible values that employee attributes can take over time.
- Tuples could represent (facts about) entities, sets of valid actual attribute values at a point in time.
This requires some tweaking.
- Properties have names and their order is insignificant, domains are nameless and ordered, so we name the domains and discard their order.
- Entities have at least one identifying attribute, tuples are unique combinations of all their domain values, so we make sure that at least one column -- a key -- represents the identifying attribute.
We end up with a table:
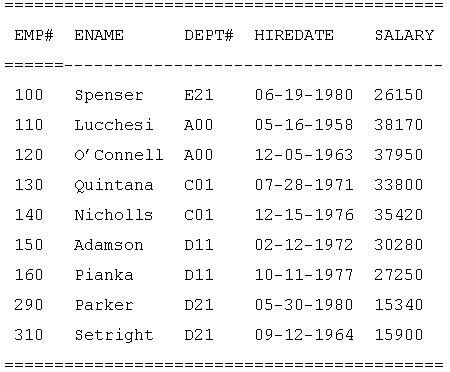
If we design tables such that:
- Columns are defined on uniquely named, unordered domains
- Rows are keyed and unordered
- There are no missing values
they have real world interpretations without losing the mathematical properties of relations. Then the relational algebra
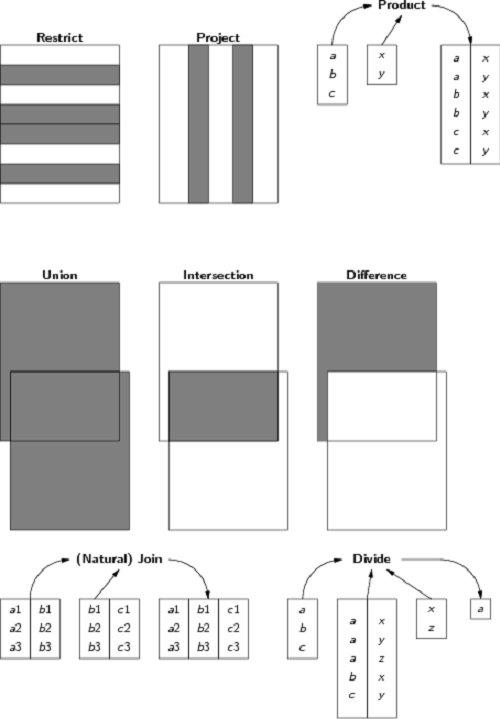
can be used to manipulate them as sets for the advantage of guaranteed provably correct results. We refer to such tables as R-tables and, if they are not, all bets are off.
'news > IT' 카테고리의 다른 글
| How to Create ISO Files From Discs on Windows, Mac, and Linux (0) | 2015.09.28 |
|---|---|
| 7 Ways To Free Up Hard Disk Space On Windows (1) | 2015.09.28 |
| 6 Alternative Browsers Based on Mozilla Firefox (0) | 2015.09.28 |
| Valuable business connections – a review for SMEs (0) | 2015.02.03 |
| 도메인 네임 시스템 (0) | 2015.02.03 |